In my previous blog post, I talked about the support libraries and the core structure of Snabb's NIC drivers. In this post, I'll talk about some of the driver improvements we made at Igalia over the last few months.
(as in my previous post, this work was joint work with Nicola Larosa)
Background
Modern NICs are designed to take advantage of increasing parallelism in modern CPUs in order to scale to larger workloads.
In particular, to scale to 100G workloads, it becomes necessary to work in parallel since a single off-the-shelf core cannot keep up. Even with 10G hardware, processing packets in parallel makes it easier for software to operate at line-rate because the time budget is quite tight.
To get an idea of what the time budget is like, see these calculations. tl;dr is 67.2 ns/packet or about 201 cycles.
To scale to multiple CPUs, NICs have a feature called receive-side scaling or RSS which distributes incoming packets to multiple receive queues. These queues can be serviced by separate cores.
RSS and related features for Intel NICs are detailed more in an overview whitepaper
RSS works by computing a hash in hardware over the packet to determine the flow it belongs to (this is similar to the hashing used in IPFIX, which I described in a previous blog post).
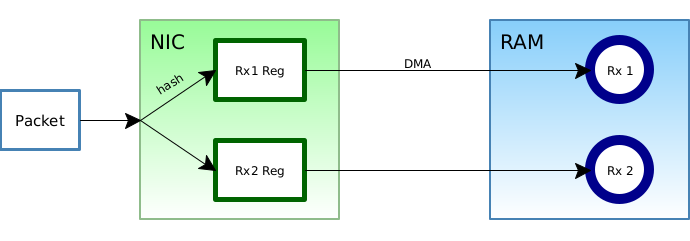
The diagram above tries to illustrate this. When a packet arrives in the NIC, the hash is computed. Packets with the same hash (i.e., they're in the same flow) are directed to a particular receive queue. Receive queues live in RAM as a ring buffer (shown as blue rings in the diagram) and packets are placed there via DMA by consulting registers on the NIC.
All this means that network functions that depend on tracking flow-related state can usually still work in this parallel setup.
As a side note, you might wonder (I did anyway!) what happens to fragmented packets whose flow membership may not be identifiable from a fragment. It turns out that on Intel NICs, the hash function will ignore the layer 3 flow information when a packet is fragmented. This means that on occasion a fragmented packet may end up on a different queue than a non-fragmented packet in the same flow. More on this problem here.
Snabb's two Intel drivers
The existing driver used in most Snabb programs (apps.intel.intel_app) worked
well and was mature but was missing support for RSS.
An alternate driver (apps.intel_mp.intel_mp) made by Peter Bristow supported
RSS, but wasn't entirely compatible with the features provided by the main
Intel driver. We worked on extending intel_mp to work as a more-or-less drop
in replacement for intel_app.
The incompatibility between the two drivers was caused mainly by lack of
support for VMDq (Virtual Machine Device Queues) in intel_mp. This is another
feature that allows for multiple queue operation on Intel NICs that is used
to allow a NIC to present itself as multiple virtualized sets of queues. It's
often used to host VMs in a virtualized environment, but can also be used
(as in Snabb) for serving logically separate apps.
The basic idea is that queues may be assigned to separate pools assigned to a VM or app with its own particular MAC address. A host can use this to run logically separate network functions sharing a single NIC. As with RSS, services running on separate cores can service the queues in parallel.
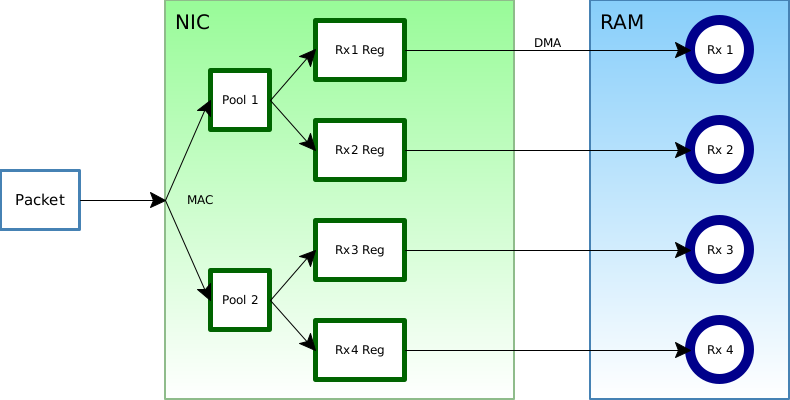
As the diagram above shows, adding VMDq changes queue selection slightly from the RSS case above. An appropriate pool is selected based on criteria such as the MAC address (or VLAN tag, and so on) and then RSS may be used.
BTW, VMDq is not the only virtualization feature on these NICs. There is also SR-IOV or "Single Root I/O Virtualization" which is designed to provide a virtualized NIC for every VM that directly uses the NIC hardware resources. My understanding is that Snabb doesn't use it for now because we can implement more switching flexibility in software.
The intel_app driver supports VMDq but not RSS and the opposite situation is
true for intel_mp. It turns out that both features can be used
simultaneously, in which case packets are first sorted by MAC address and then
by flow hashing for RSS. Basically each VMDq pool has its own set of RSS queues.
We implemented this support in the intel_mp driver and made the driver
interface mostly compatible with intel_app so that only minimal modifications
are necessary to switch over. In the process, we made bug-fixes and performance
fixes in the driver to try to ensure that performance and reliability are
comparable to using intel_app.
The development process was made a lot easier due to the existence of the
intel_app code that we could copy and follow in many cases.
The tricky parts were making sure that the NIC state was set correctly when
multiple processes were using the NIC. In particular, intel_app can rely on
tracking VMDq state inside a single Lua process.
For intel_mp, it is necessary to use locking and IPC (via shared memory) to
coordinate between different Lua processes that are setting driver state. In
particular, the driver needs to be careful to be aware of what resources (VMDq
pool numbers, MAC address registers, etc.) are available for use.
Current status
The driver improvements are now merged upstream in intel_mp, which is now the
default driver, and is available in the Snabb 2017.11 "Endive" release.
It's still possible to opt out and use the old driver in case there
are any problems with using intel_mp. And of course we appreciate any bug
reports or feedback.