Today's post is about the compiler implementation work I've been doing at
Igalia for the past month and a half or so.
The networking team at Igalia
maintains the pflua library for fast packet
filtering in Lua. The library implements the pflang
language, which is what we call the filtering language that's built into tools like
tcpdump and libpcap.
The main use case for pflua is packet filtering integrated into programs written using Snabb, a high-speed networking framework implemented with LuaJIT.
(for more info about pflua, check out Andy Wingo's blog posts about it and also Luke Barone-Adesi's blog posts.
The big selling point of pflua is that it's a very high speed implementation of pflang filtering (see here). Pflua gets its speed by compiling pflang expressions clevery (via ANF and SSA) to Lua code that's executed by LuaJIT, which makes code very fast via tracing JIT compilation.
Compiling to Lua lets pflua take advantage of all the optimizations of LuaJIT, which is great when compiling simpler filters (such as the "accept all" filter) or with filters that reject packets quickly. With more complex filters and filters that accept packets, the performance can be more variable.
For example, the following chart from the pflua benchmark suite shows a situation in which benchmarks are paired off, with one filter accepting most packets and the second rejecting most. The Lua performance (light orange, furthest bar on the right) is better in the rejecting case:
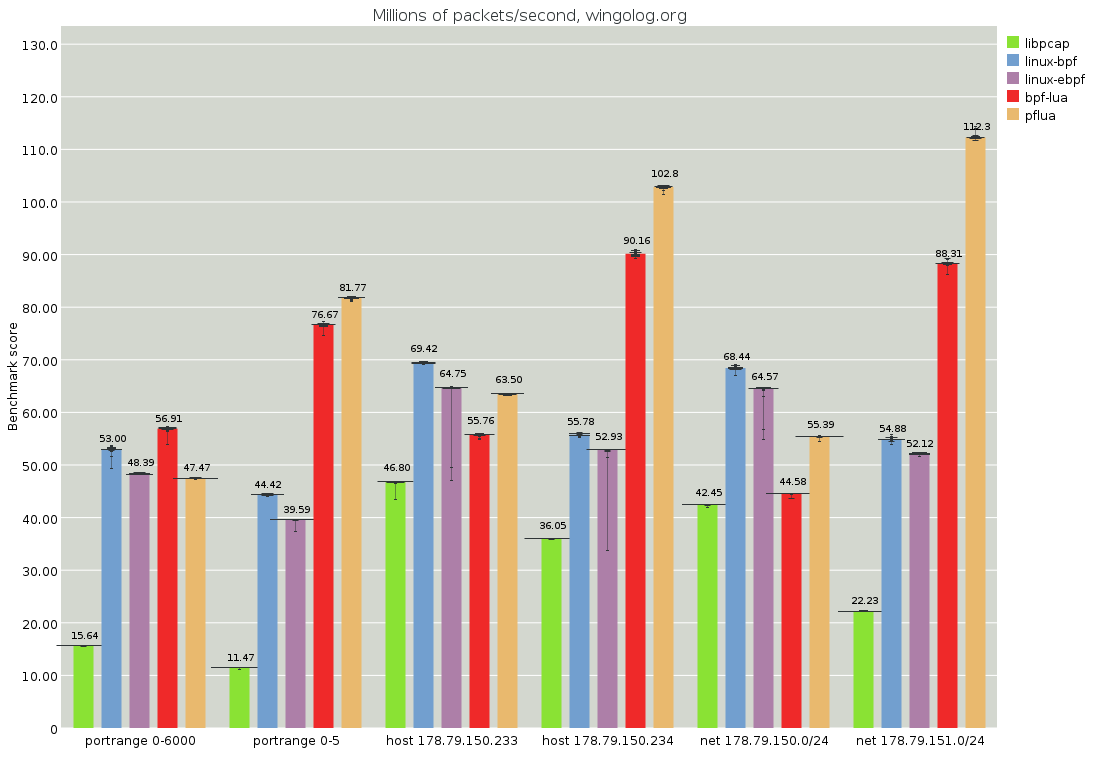
Meanwhile, for filters that mostly accept packets, the Linux BPF implementations (blue & purple) are faster. As Andy explains in his original blog post on these benchmarks, this poor performance can be attributed to the execution of side traces that jump back to the original trace's loop header, thus triggering unnecessary checks.
That brings me to what I've been working on. Instead of compiling down to Lua and relying on LuaJIT's optimizations, I have been experimenting with compiling pflang filters directly to x64 assembly via pflua's intermediate representation. The compilation is still implemented in Lua and for its code generation pass utilizes dynasm, a dynamic assembler that augments C/Lua with a preprocessor based assembly language (it was originally developed for use with C in the internals of LuaJIT). More precisely, the compiler uses the Lua port of dynasm.
The hope is that by compiling to x64 asm directly, we can get better performance out of cases where compiling to Lua does poorly. To spoil the ending, let me show you the same benchmark graph from earlier but with a newer Pflua and the new native backend (in dark orange on the far right):
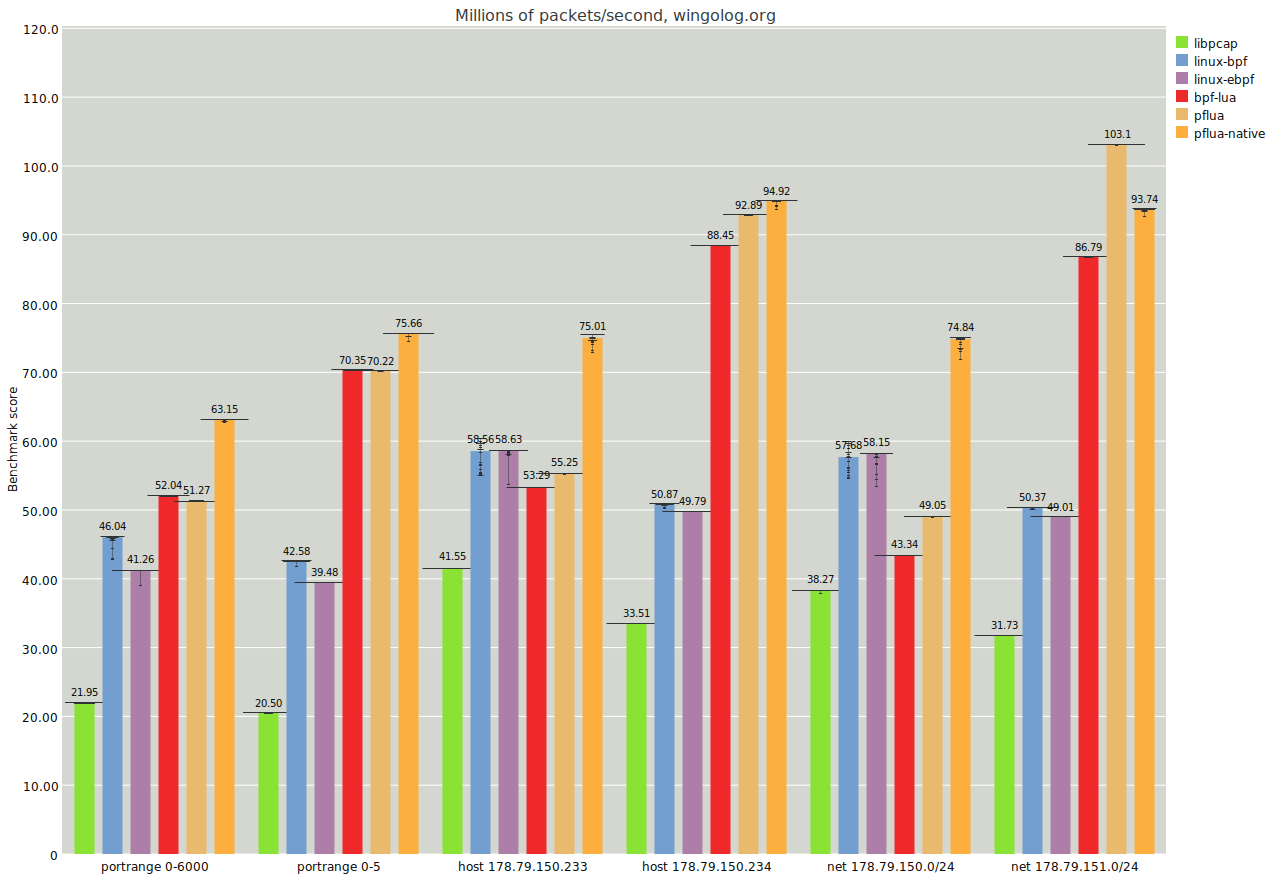
As you can see, the performance of the native backend is almost uniformly better than the other implementations on these particular filters. The last case is the only one in which the default Lua backend (light orange, 2nd from right) does better.
In particular, the native backend does better than the Linux BPF cases even when the filter tends to accept packets. That said, I don't want to give the impression that the native backend is always better than the Lua backend. For example, the Lua backend does better in the following examples:
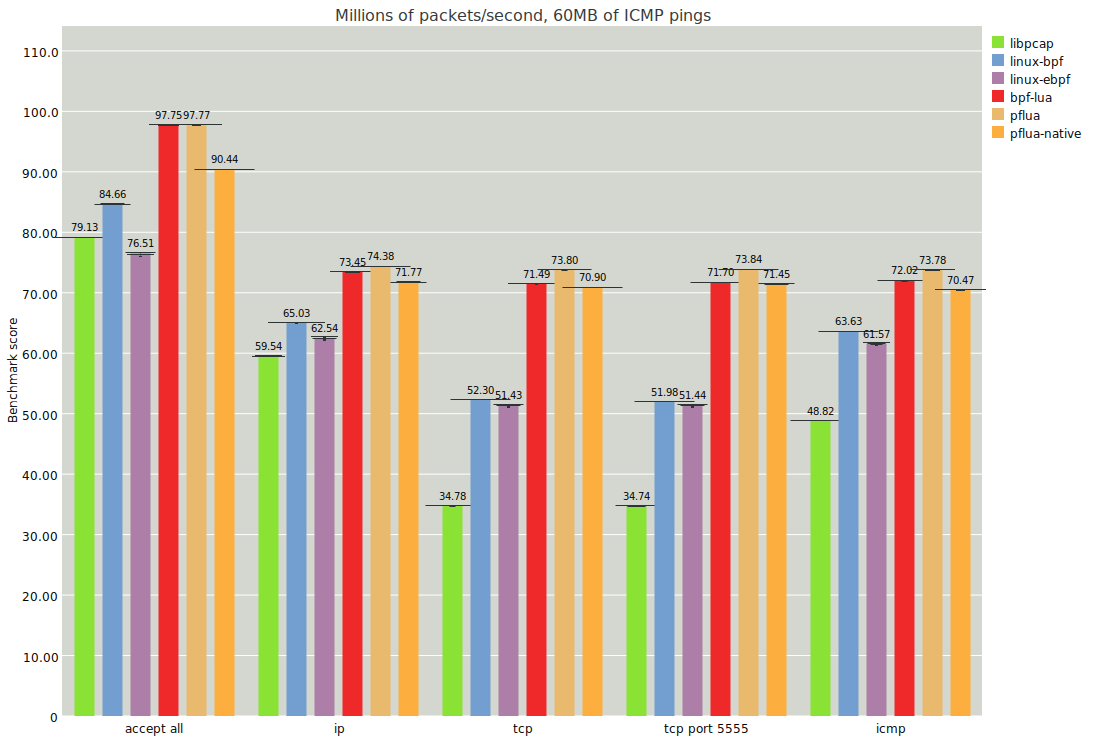
Here the filters are simpler (such as the empty "accept all" filter) and execute fewer checks. In these cases, the Lua backend is faster, perhaps because LuaJIT does a good job of inlining away the checks or the funtion entirely. The native backend is still competitive though.
Using filters that are more complex appears to tip things favorably towards the dynasm backend. For example, here are the results on two more complex filters that target HTTP packets:
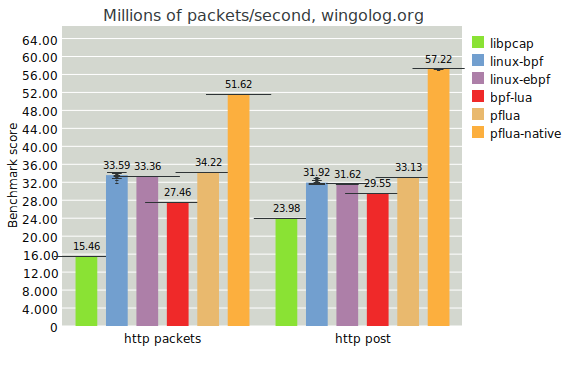
The two filters used for the graph above are the following:
tcp port 80 and
(((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)
tcp[2:2] = 80 and
(tcp[20:4] = 1347375956 or
tcp[24:4] = 1347375956 or
tcp[28:4] = 1347375956 or
tcp[32:4] = 1347375956 or
tcp[36:4] = 1347375956 or
tcp[40:4] = 1347375956 or
tcp[44:4] = 1347375956 or
tcp[48:4] = 1347375956 or
tcp[52:4] = 1347375956 or
tcp[56:4] = 1347375956 or
tcp[60:4] = 1347375956)
The first is from the pcap-filter language manpage and targets HTTP data packets. The other is from a Stackexchange answer and looks for HTTP POST packets. As is pretty obvious from the graph, the native backend is winning by a large margin for both.
Implementation
Now that you've seen the benchmark results, I want to remark on the general
design of the new backend. It's actually a pretty straightforward
compiler that looks like one you would write following Appel's
Tiger book.
The new backend consumes the SSA basic blocks IR that's used by the Lua backend.
From there, an instruction selection pass converts the tree structures in the
SSA IR into straight-line code with virtual instructions,
often introducing additional variables (really virtual registers) and movs
for intermediate values.
Then a simple linear scan register allocator
assigns real registers to the virtual registers, and also eliminates redundant
mov instructions where possible. I've noticed that most pflang filters don't
produce intermediate forms with much register pressure, so spilling to memory
is pretty rare. In fact, I've only been able to cause spilling with synthetic
examples that I make up or from random testing outputs.
Finally, a code generation pass uses dynasm to produce real x64 instructions. Dynasm simplifies code generation quite a bit, since it lets you write a code generator as if you were just writing inline assembly in your Lua program.
For example, here's a snippet showing how the code generator produces assembly for a virtual instruction that converts from network to host order:
elseif itype == "ntohl" then
local reg = alloc[instr[2]]
| bswap Rd(reg)
This is a single branch from a big conditional statement that dispatches on the type of
virtual instruction. It first looks up the relevant register for the argument
variable in the register allocation and then produces a bswap assembly instruction.
The line that starts with a | is not normal Lua syntax; it's consumed by
the dynasm preprocessor and turned into normal Lua.
As you can see, Lua expressions like reg can also be used in the assembly to
control, for example, the register to use.
After preprocessing, the branch looks like this:
elseif itype == "ntohl" then
local reg = alloc[instr[2]]
--| bswap Rd(reg)
dasm.put(Dst, 479, (reg))
(there is a very nice unofficial documentation page for dynasm by Peter Crawley if you want to learn more about it)
There are some cases where using dynasm has been a bit frustrating. For example, when
implementing register spilling, you would like to be able to switch between using
register or memory arguments for dynasm code generation (like in the Rd(reg) bit
above). Unfortunately, it's not possible
to dynamically choose whether to use a register or memory argument, because it's
fixed at the pre-processing stage of dynasm.
This means that the code generator has to separate register and memory cases for every
kind of instruction that it dispatches on (and potentially more than just two cases
if there are several arguments). This turns the code into spaghetti with quite a bit of
boilerplate. A better alternative is to introduce additional instructions
to mov memory values into registers and vice versa, and then uniformly work on
register arguments otherwise. This introduces some unnecessary overhead, but since
spilling is so rare in practice, I haven't found it to be a problem in practice.
Dynasm does let you do some really cute code though. For example, one of the tests that I wrote ensures that callee-save registers are used correctly by the native backend. This is a little tricky to test because you need to ensure that compiled function doesn't interfere with registers used in the surrounding context (in this case, that's the LuaJIT VM).
But expressing that test context is not really possible with just plain old Lua. The solution is to apply some more dynasm, and set up a test context which uses callee-save registers and then checks to make sure its registers don't get mutated by calling the filter. It ends up looking like this:
local function test(expr)
local Dst = dasm.new(actions)
local ssa = convert_ssa(convert_anf(optimize(expand(parse(expr),
"EN10MB"))))
local instr = sel.select(ssa)
local alloc = ra.allocate(instr)
local f = compile(instr, alloc)
local pkt = v4_pkts[1]
| push rbx
-- we want to make sure %rbx still contains this later
| mov rbx, 0xdeadbeef
-- args to 'f'
| mov64 rdi, ffi.cast(ffi.typeof("uint64_t"), pkt.packet)
| mov rsi, pkt.len
-- call 'f'
| mov64 rax, ffi.cast(ffi.typeof("uint64_t"), f)
| call rax
-- make sure it's still there
| cmp rbx, 0xdeadbeef
-- put a bool in return register
| sete al
| pop rbx
| ret
local mcode, size = Dst:build()
table.insert(anchor, mcode)
local f = ffi.cast(ffi.typeof("bool(*)()"), mcode)
return f()
end
What this Lua function does is it takes a pflang filter expression and compiles it
into a function f, and then returns a new function generated with
dynasm that will call f with particular values in callee-save registers. The
generated function only returns true if f didn't stomp over its registers.
You can see the rest of the code that uses this test here. I think it's a pretty cool test.
Using the new backend
If you'd like to try out the new Pflua, it's now merged into the upstream Igalia repository here. To set it up, you'll need to clone the repo recursively:
git clone --recursive https://github.com/Igalia/pflua.git
in order to pull in both LuaJIT and dynasm submodules.
Then enter the directory and run make to build it.
To check out how the new backend compiles some filters, go into
the tools folder and run something like this:
$ ../env pflua-compile --native 'ip'
7f4030932000 4883FE0E cmp rsi, +0x0e
7f4030932004 7C0A jl 0x7f4030932010
7f4030932006 0FB7770C movzx esi, word [rdi+0xc]
7f403093200a 4883FE08 cmp rsi, +0x08
7f403093200e 7403 jz 0x7f4030932013
7f4030932010 B000 mov al, 0x0
7f4030932012 C3 ret
7f4030932013 B001 mov al, 0x1
7f4030932015 C3 ret
and you'll see some assembly dumped to standard output like above. If you have any code
that uses pflua's API, you can pass an extra argument to pf.compile_filter
like the following:
pf.compile_filter(filter_expr, { native = true })
in order to use native compilation. The plan is to integrate this new work into Snabb (normal pflua is already integrated upstream) in order to speed up network functions that rely on packet filtering. Bug reports and contributions welcome!