My first task when I joined Igalia was experimenting with building networking apps with pfmatch and the Snabb framework. I mentioned Snabb in my last blog post, but in case you're just tuning in, Snabb is a framework built on LuaJIT that lets you assemble networking programs as a combination of small apps---each implementing a particular network function---in a high-level scripting environment.
Meanwhile, pfmatch is a simple DSL that's built on pflua, the subject of my last blog post. The idea of pfmatch is to use pflang filters to implement a pattern-matching facility for use in Snabb apps.
While pfmatch has been a part of pflua for a while, the networking team hadn't really tried using it for a real app. So as a starter project, I looked into implementing a small and self-contained app using pfmatch that could potentially be useful. After looking through a bunch of networking literature, I settled on building an app for suppressing potentially malicious traffic, such as portscans, from outside your network.
A portscan detector is a good fit for a Snabb app because it can be built as a self-contained network function that pushes good packets through to other apps and drops the bad ones.
There are many online algorithms used for solving this problem, many based on Jung et al's well-known TRW (threshold random walk) work. A related algorithm by Weaver et al in "Very Fast Containment of Scanning Worms" from Usenix Security 2004 came with easy-to-understand pseudo-code for implementing the algorithm, so I went with that version.
I won't describe the detailed workings of the TRW algorithm or its variants here because the papers I linked to explain the ideas better than I could. I'll just sketch the basic idea here.
The family of TRW-like algorithms essentially try to quickly block traffic from hosts that will not be "useful" in the future. To a first approximation, this means traffic that will not lead to successful connections (the algorithm assumes the presence of an oracle for determining connection success). A successful connection "drives a random walk upwards" and vice versa for a failed one---when the walk reaches a certain threshold the host is assumed to be malicious. This works on the assumption that non-malicious hosts have a higher probability for connection success.
The fast algorithm from the Weaver paper uses the basic TRW algorithm but tracks the connection data using approximate caches in order to reduce memory use and improve access speed. (there are a few other differences from TRW that are detailed in section 5.1 of the paper)
Implementation
I'll use the previously mentioned scan suppression app as an example to walk through some of the interesting points in building a Snabb app.
(Note: this isn't intended to be a tutorial on how to build a Snabb app, so you may want to look at Snabb's Getting Started guide for more details)
Let's start with the data definitions that the app uses. The algorithm in the Usenix paper is designed to be fast by utilizing data structures optimized for space usage. Take a look at Figure 1 from the paper linked below:
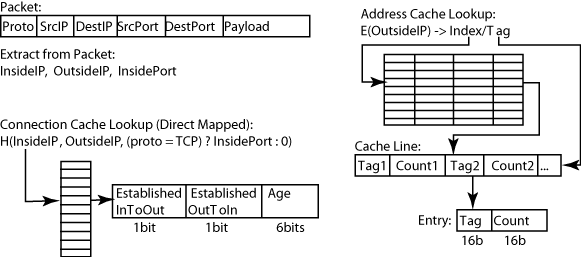
The figure shows two cache tables that are used in the algorithm. The thing to notice is that one of the caches uses 8-bit records and the other uses 64 bits per record. It'd be useful to ensure that the data structures we use in the Lua code match this without additional overhead.
To do that, we can use the FFI to declare the data structures using C declarations like this:
ffi.cdef[[
typedef struct {
uint8_t in_to_out : 1;
uint8_t out_to_in : 1;
uint8_t age : 6;
} conn_cache_line_t;
typedef struct {
uint16_t tag1;
uint16_t count1;
uint16_t tag2;
uint16_t count2;
uint16_t tag3;
uint16_t count3;
uint16_t tag4;
uint16_t count4;
} addr_cache_line_t;
]]
This declaration uses bit fields for the connection cache record structs to ensure that we fit the data in a byte. It's pretty nice to be able to specify FFI data types like this in LuaJIT, even when we're not specifically binding to FFI functions. The rest of the data structure implementation follows the paper straightforwardly.
For the actual app code, it's helpful to know what makes up a Snabb app.
At its simplest, a Snabb
app is a Lua class that has a new method. But usually it also has either a pull or push method
to either pull packets into the program or push packets through, depending on the network function
it implements.
The Snabb framework calls these methods on every breath of its core loop, shuffling packets around as necessary.
So to build the scanner, we need an app with a push method that takes packets (from somewhere,
the precise input will depend on how the app is used) and drops them if they're believed
to be malicious and transmits them on otherwise. The push method will call out to a function
implementing the algorithm in the Weaver et al paper.
(Note: the Snabb Reference Manual explains what methods an app can implement along with many other details about the framework)
The main components of the algorithm are shown in Figure 2 of the Usenix paper:

These three cases distinguish whether a packet comes from inside/outside the network in question and whether it triggers the blocking threshold. For scan suppression purposes, the "inside" might be a specific subnet that you control and "outside" all other (potentially malicious) hosts. Alternatively, inside and outside may be flipped if you're trying to contain scanning worms.
These three cases are encoded in two methods, inside and outside, in the
Scanner class for the app.
The push method eventually calls these methods, but first it has to dispatch
to determine which of these three cases we're going to run. Thus the push method
looks like this:
function Scanner:push()
-- some sanity checks and variable binding for convenience
local i = assert(self.input.input, "input port not found")
local o = assert(self.output.output, "output port not found")
-- in the actual app there's some code here that does some
-- maintenance work on a timer, but the details don't matter here
-- wait until we get a packet to process
while not link.empty(i) do
-- this part is a little different from what's in the Git repo just
-- to simplify the code for this blog post
local pkt = link.receive(i)
self:matcher(pkt.data, pkt.length)
end
end
The most important line is the self:matcher(pkt.data, pkt.length) line, which
is calling a pfmatch function that's installed in constructor for Scanner. The
code that constructs the dispatcher looks like this:
self.matcher = pfm.compile([[
match {
ip and src net $inside_net and not dst net $inside_net => {
ip proto tcp => inside($src_addr_off, $dst_addr_off, $tcp_port_off)
otherwise => inside($src_addr_off, $dst_addr_off)
}
ip and not src net $inside_net and dst net $inside_net => {
ip proto tcp => outside($src_addr_off, $dst_addr_off, $tcp_port_off)
otherwise => outside($src_addr_off, $dst_addr_off)
}
}]],
In this code, each of the clauses in the match clause (which is actually a Lua
string between the [[ and ]]---so not quite as seamless as a Lisp DSL) has
a pflang filter on the left-hand side and some actions on the right-hand side.
The outermost filters in this case are checking whether packets are coming from some
configured network or from outside.
(Note: this makes the simplifying assumption that you can determine whether a
packet comes from inside/outside the network with a src net ... filter)
The actions are either nested dispatches, or a call to some method in self.
The specific nested filters in this example are checking whether the packet is
TCP or not (the algorithm cares about the port if it's TCP, but not otherwise).
The $-prefixed expressions like $inside_net are substitutions that let you
do a tiny bit of abstraction over patterns and actions
(they're just strings that are substituted into the filter or action).
Though it's possible to write this dispatching without pfmatch, I think it
looks clearer written this way than with conditionals and helper functions
to match on the packet fields.
The inside and outside methods themselves are almost straightforward
transliterations of the pseudo-code. For example, here is the inside method
that handles the first case on the left:
function Scanner:inside(data, len, off_src, off_dst, off_port)
-- do a lookup in the connection cache
local cache_entry, src_ip, dst_ip, port =
self:extract(data, off_src, off_dst, off_port)
-- do a lookup in the address cache
count = self:lookup_count(dst_ip)
if cache_entry.in_to_out ~= 1 then
if cache_entry.out_to_in == 1 then
-- previously a "miss" but now a "hit"
self:set_count(dst_ip, count - 2)
end
cache_entry.in_to_out = 1
end
cache_entry.age = 0
-- forward packet to next app
link.transmit(self.output.output, self.pkt)
end
As you can see, the structure of this method is identical to the conditional in the figure. The outside case is a little more complicated:
function Scanner:outside(data, len, off_src, off_dst, off_port)
local cache_entry, src_ip, dst_ip, port =
self:extract(data, off_src, off_dst, off_port)
count = self:lookup_count(src_ip)
-- here we dispatch between the two block threshold cases that you can see
-- in Figure 2
if count < block_threshold then
if cache_entry.out_to_in ~= 1 then
if cache_entry.in_to_out == 1 then
self:set_count(src_ip, count - 1)
cache_entry.out_to_in = 1
elseif hygiene_matcher(self.pkt.data, self.pkt.length) then
if debug then
print("blocked packet due to hygiene check")
end
return packet.free(self.pkt)
else
-- a potential "miss"
self:set_count(src_ip, count + 1)
cache_entry.out_to_in = 1
end
cache_entry.in_to_out = 1
end
-- if not dropped ...
cache_entry.age = 0
link.transmit(self.output.output, self.pkt)
-- i.e., above block threshold
else
if cache_entry.in_to_out == 1 then
if syn_or_udp_matcher(self.pkt.data, self.pkt.length) then
if debug then
print("blocked initial SYN/UDP packet for blocked host")
end
return packet.free(self.pkt)
elseif cache_entry.out_to_in ~= 1 then
-- a "hit"
self:set_count(src_ip, count - 1)
cache_entry.out_to_in = 1
end
-- internal or old
cache_entry.age = 0
link.transmit(self.output.output, self.pkt)
else
if debug then
print(string.format("blocked packet from %s on port %d",
format_ip(src_ip), port))
end
return packet.free(self.pkt)
end
end
end
Here we've merged the two cases of being above or below the threshold into a single method with a big conditional. Despite the length of the method, the structure still matches the pseudo-code very closely. If you can figure out what the helper functions that are used will do, the code is pretty obvious given the algorithm pseudo-code.
Reflection
Though I set out to build an app using pfmatch, it turned out that the lines
of code for matching is fairly small relative to the whole app. That said, I do
think it makes the dispatch code cleaner than it would look without it.
On the other hand, I'm used to more seamless Lispy DSLs via macros (see Racket) so I do wish that Lua came with macros (though from what I heard at the Lua Workshop it may not be a total pipe dream).
In the full code, there are also a couple of places
where I didn't use pfmatch but did compile some pflua filters for use in the
inside/outside methods. In these cases, it was clearer to dispatch on a boolean
with a conditional than use a match clause.
I think we could improve some things in pfmatch to make it more useful. For
example, using substitutions is really necessary to make the code look clean
but it's kinda hacky. It would've been nicer if the the
pattern language supported data deconstruction/variable binding in addition to
data dispatch, so that this could be done less awkwardly. It's not obvious to
me how that would integrate into pflang though.
Perhaps instead the pfmatch language could come with more built-in substitutions
that encode the structure of packets, so that expressions in both pflang and the
actions can refer to them by name instead of ip[12:4].
Overall, I'm also impressed that it's so easy to write a network function in Lua following the structure of some code from a paper. This is partly to the credit of the paper authors who wrote a clear paper, but also shows how nice it is to program networking code in a high-level language.
The full app code is available here.